Claudeのデータ取り扱いと安全性を解説 -- 入力は学習に使われるのか
Claudeに入力したデータがモデル学習に使われるかを、消費者向け(Free/Pro/Max)と商用・API別に整理。データ保持期間の違い(30日と5年)、設定での選択方法、Constitutional AIによる安全設計の仕組みまで解説する。
この記事は「Claude入門ガイド2026年版」の関連記事です。
「Claudeに入力したデータは、AIの学習に使われるのだろうか」——Claudeを使い始めた多くの人が最初に抱く疑問だ。
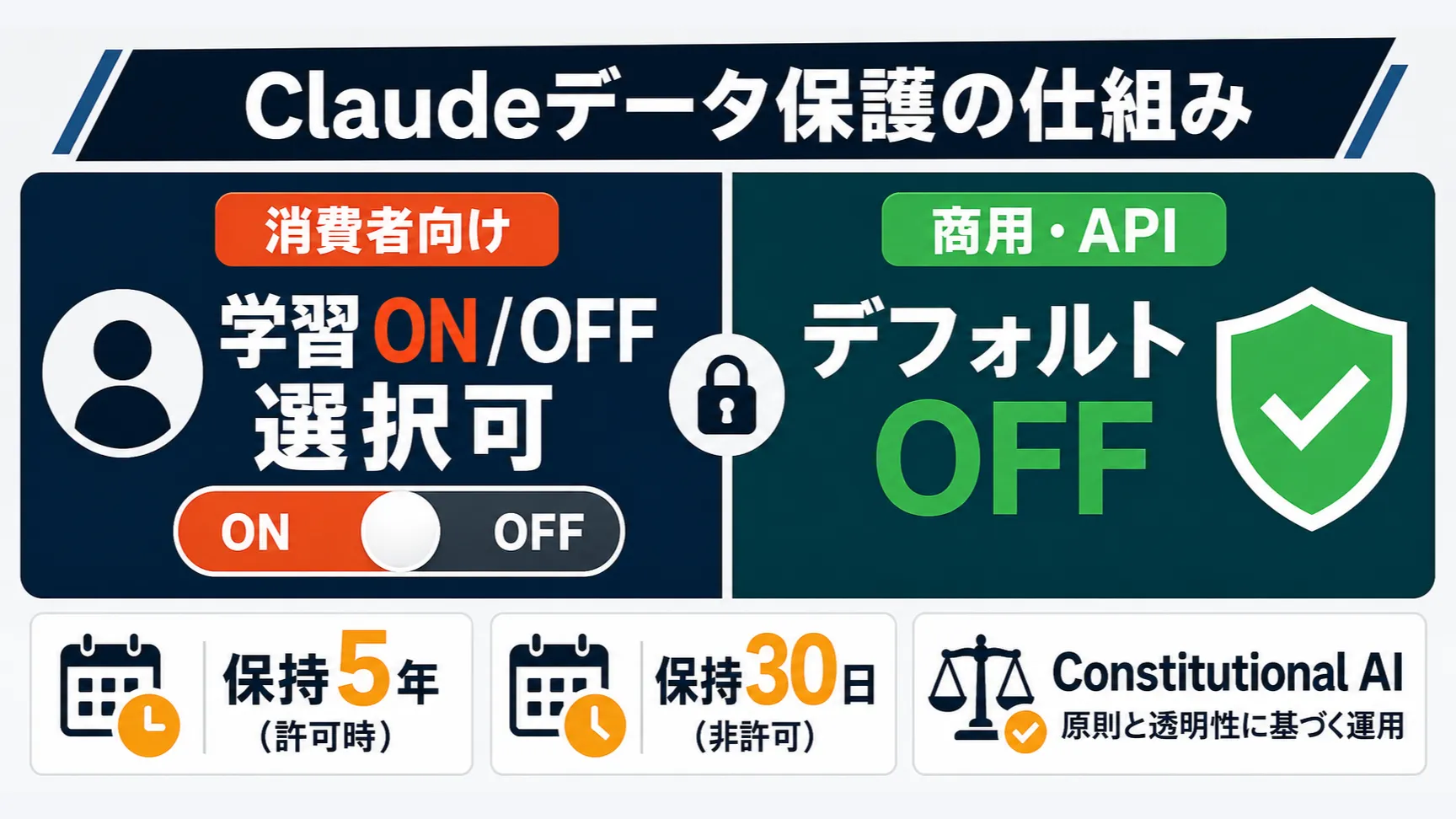
結論から述べる。消費者向けプラン(Free / Pro / Max)では、ユーザー自身が学習利用を許可するかどうかを選択できる。商用プラン(Team / Enterprise)やAPIを直接利用する場合は、デフォルトで入力・出力はモデル学習に使われない。
プランによってデータの扱いが根本的に異なるこの仕組みを理解しておくだけで、日常利用から企業導入の判断まで行動の根拠が明確になる。
本記事では2026年6月時点のAnthropicの公式ポリシーに基づき、プラン別のデータ取り扱い・保持期間・設定変更の手順・Constitutional AIによる安全設計を整理する。読了後、自分のプランに必要な設定を判断できる状態になることが本記事のゴールだ。
まず結論 — 入力データは学習に使われるのか
Claudeに関するデータポリシーの骨格は、「消費者向けか商用・APIかで仕組みが根本的に異なる」という一点に集約される。
| プラン | デフォルトの学習利用 | ユーザー側の選択肢 |
|---|---|---|
| Free / Pro / Max(個人) | ユーザーが選択 | 許可 or 不許可を設定で変更可 |
| Claude Code(Free/Pro/Maxアカウント経由) | 上記に準じる | 同上 |
| Team / Enterprise / Government / Education | デフォルト:不使用 | 明示的オプトイン時のみ |
| API(Bedrock / Vertex AI 経由含む) | デフォルト:不使用 | 明示的オプトイン時のみ |
ここで一度、問いを置きたい。
「自分が使っているのはどのプランか」——この確認だけで、以下の節を読む視点が変わる。
消費者向け(Free / Pro / Max)のデータ学習ポリシー
消費者向けプランでは、ユーザーが学習利用を許可するかどうかを設定から選択できる。現時点では、設定でいつでも変更が可能だ。
ユーザーが「許可」した場合
学習利用を許可すると、新規・再開したチャットおよびClaude Codeのコーディングセッションが対象になる。入力したプロンプトと生成された回答が、Anthropicのモデル改善に利用される可能性がある。
ユーザーが「不許可」にした場合
設定で学習利用をオフにした場合、会話データはモデルのトレーニングに使われない。ただし、サービス提供に必要な処理(安全性チェックや不正利用の防止など)のためにデータが参照される場合はある。
設定の変更方法
設定は次の手順で確認・変更できる。
- claude.ai にログインし、右上のアカウントアイコンをクリック
- 「設定(Settings)」を開く
- 「プライバシー(Privacy)」セクションを確認する
- 「AI学習の改善のためにデータを使用する」の項目をオン/オフで切り替える
設定変更は即時に反映される。一度許可したとしても、後から設定を変えることができる。
データ保持期間 — 学習の可否で変わる30日と5年
ここまでで学習利用の「可否を選べる」仕組みを整理した。次は、そのデータが「いつまで保持されるか」という保持期間の話に移る。
保持期間の違いは大きい。
| 設定 | 保持期間 |
|---|---|
| 学習利用を許可した場合 | 5年間(新規・再開のチャットとClaude Codeのセッション) |
| 学習利用を許可しない場合 | 30日間(従来通り) |
この5年という数字は、Anthropicが2025年10月に更新した消費者向け規約で明示されたものである(出典:Anthropic Consumer Terms Update)。
重要なのは次の点だ。
会話を削除すれば、その会話は将来のモデル学習の対象から外れる。
会話履歴の削除は、サイドバーから個別に行うか、設定画面の「会話の削除」からまとめて実行できる。機密情報を誤って入力した場合や、定期的なデータ整理の際に活用したい。
商用・API利用はデフォルトで学習に使われない
消費者向けプランとは対照的に、商用・APIプランではデータ取り扱いの基本方針が異なる。
Team / Enterprise / Government / Education、および API(Amazon Bedrock・Google Vertex AI 経由を含む)を利用する場合、入力・出力データはデフォルトでモデル学習に使われない。
これはAnthropicの公式サポートページでも明確に記載されている(出典:Is my data used for model training? - Anthropic Help)。
なぜ商用・APIはデフォルトでオフなのか
企業が扱うデータには、顧客情報・契約内容・内部ドキュメントといった機密性の高いものが含まれる。これらを意図せずモデル学習に提供するリスクは商用利用において許容されないため、Anthropicは商用向けにデフォルトをオフに設定している。
「企業データを守る」という設計が、商用プランのデフォルト設定そのものに組み込まれている。
企業導入における追加の安全措置
EnterpriseプランおよびAPI契約では、データ処理地域の指定や、ゼロデータリテンション(ZDR:入力データを保持・学習に一切使用しない契約オプション)の適用など、追加の安全措置が利用できる場合がある。詳細はAnthropicの営業窓口で確認するとよい。
Constitutional AIとは — Anthropicの安全思想
ここまではデータポリシーの話をしてきた。もう一つの「安全性」の柱として、Claudeの設計そのものに組み込まれた安全思想にも触れておきたい。
「憲法」を持つAI
Constitutional AI(CAI)とは、Anthropicが開発した安全手法の名称だ。日本語に訳せば「憲法的AI」——字義通り、AIに「憲法(原則集)」を与え、それに照らして自らの出力を評価・修正させる仕組みである。
一般的なAI安全性向上の手法では、人間のフィードバックによる強化学習(RLHF)が使われる。これは人間のアノテーターが「良い回答」「悪い回答」を大量に評価することでモデルを改善する方法だ。
Constitutional AIはこれを拡張する。原則集(「他者を傷つける指示には従わない」「正直であり続ける」などの条項)を与え、モデル自身が自分の回答をその原則で批判・修正するプロセスを学習に組み込む。人間フィードバックの代わりにAI生成フィードバックを用いた強化学習(RLAIF:Reinforcement Learning from AI Feedback)も採用している(出典:Constitutional AI: Harmlessness from AI Feedback - Anthropic Research)。
結果として「有害なことを言わないよう訓練された」モデルではなく、「なぜ有害なのかを自分で評価できる」モデルに近づく、というのがAnthropicの主張だ。
なぜこれがユーザーにとって重要か
Constitutional AIはプライバシーとは直接関係しないが、Claudeが「なぜそう回答するか」の根拠として機能している。倫理的な問いに対して回答を拒否したり、依頼内容に潜む問題点を指摘したりする挙動の背後には、この設計がある。
データ取り扱いの信頼性と、モデルの設計上の安全性は、互いに補完し合う形でAnthropicの信頼基盤を構成している。
企業・業務で安全に使うために
ここまでの内容を踏まえ、企業・業務用途でClaudeを活用する際の具体的な方針を整理する。
最初の一歩として確認すべきことは、「どのプランを使っているか」だ。個人のClaude.aiアカウント(Free/Pro/Max)で業務データを扱うのと、Teamプランや企業向けAPIで使うのとでは、データポリシーが根本的に異なる。
業務ナレッジを安全にClaudeと組み合わせる具体的な設定方法については、Claude Projectsで業務ナレッジを安全に運用する設定ガイドを参照してほしい。また、部署や職種ごとの具体的な活用パターンはClaude企業活用事例ガイドでまとめている。
個人ユーザーの設定チェックリスト
消費者向けプラン(Free / Pro / Max)を使っている場合、以下の項目を確認しておくことを推奨する。
確認事項
- 現在の学習利用設定を確認する — claude.ai の「設定 → プライバシー」で現在の状態を確認する
- 機密情報を含む会話を削除する — パスワード・個人情報・業務機密を含む過去の会話はサイドバーから削除できる
- プランの目的と設定を一致させる — 業務利用が主目的であれば、学習利用をオフにするか、Team/Enterpriseへの移行を検討する
- Claude Code 利用者はアカウントの設定を確認 — Claude Codeも Free/Pro/Maxアカウント経由の場合、同じプライバシー設定が適用される
設定を「許可」のままにしておくかどうかは、利用目的次第だ。個人的な学習・情報収集・趣味の利用であれば、モデル改善に貢献することに問題を感じない人も多い。一方で、業務関連の情報・個人を特定できるデータ・他者のプライバシーに関わる情報が混じる場合は、オフにしておく方が賢明だ。
FAQ
Q: 有料プラン(Pro / Max)にすれば学習に使われなくなるか?
A: いいえ。 有料プランかどうかは、データの学習利用ポリシーに影響しない。学習利用を止めたい場合は、プランに関わらず設定からオフにする必要がある。
Q: 過去の会話を削除すれば、既に使われたデータも消えるか?
A: 将来の学習対象からは外れる。 会話を削除することで、その会話は今後のモデル学習に使われなくなる。ただし、削除以前にすでに学習処理が行われていた場合、そのデータの影響を遡及的に取り除くことはできない、とAnthropicのポリシーは説明している。
Q: APIを使って開発しているが、テスト中のプロンプトも学習されるか?
A: デフォルトではされない。 API(Bedrock・Vertex AI経由を含む)を利用している場合、入力・出力データはデフォルトでモデル学習に使われない。明示的にオプトインしない限り、開発中のプロンプトや出力は学習対象外だ。
Q: ポリシーはいつ変わるか分からないのでは?
A: 変わりうる。 本記事は2026年6月時点のポリシーに基づく。最新情報はAnthropicプライバシーページで確認することを推奨する。ポリシー変更時にはAnthropicからメール通知が行われる。
まとめ
本記事では、Claudeのデータ取り扱いをプラン別に整理した。要点は一文に尽きる。
「消費者向けは自分で選択でき、商用・APIはデフォルトで学習に使われない」
個人利用者であれば設定画面での確認、業務利用者であれば利用プランの見直しが次の一手だ。データポリシーは変わりうるため、Anthropic公式のプライバシー情報を定期的に確認しておくことを推奨する。
Claudeの全体像は「Claude入門ガイド2026年版」で確認できる。
執筆
AI通信 編集部
AIが社会・ビジネス・日常へ浸透する構造を、官公庁・調査機関・一次論文のデータで追っています。速報より文脈、感覚より数字——変化の「なぜ」を理解することで、次の動きが読める記事を目指しています。
この記事をシェア
関連記事
- Claude Fable 5 完全ガイド——Mythosクラスとは何か・料金・ユースケース
Claude Fable 5・Mythos 5は2026年7月1日に提供再開。有料プランでは7月19日までサブスク内で利用でき、以降は従量課金へ移行予定。本記事は100万トークン・料金・Mythosクラス等の仕様を整理する。
- Claude.aiの始め方 -- 登録・設定・初回操作の全手順
Claude.aiのアカウント作成方法(メール・Google・Apple)から、Web版・iOS/Androidアプリ・デスクトップアプリの導入手順、初回チャットのコツ、無料/Proプランの選び方まで初心者向けに解説した2026年最新ガイドです。
- Claude Artifactsの使い方 -- 生成物を編集・公開する
Claude Artifactsでコード・文書・図・Webアプリを専用ウィンドウで生成・編集・共有する方法を解説。バージョン管理・MCP連携による対話型アプリ作成・全プランで使える共有機能・永続ストレージの条件まで2026年6月最新情報をまとめた。